

| Note: The Good Place was an NBC sitcom that aired from 2016 to 2020. If you’ve seen it, I hope you’ll enjoy the references. If not, no worries—you’ll still get all the value from the technical guidance here (and maybe be inspired to check out the show later!). |
When disaster strikes your AWS-based workload (What is a disaster?), there is a bad place you can send your users (the AWS Region where the disaster occurred) and a good place you can send them (your recovery Region). Don’t worry, because I will show you here how to ensure they end up in the good place.
In order to even have a good place (recovery Region) to send them to, first you have to implement and execute one of the disaster recovery strategies. This blog post assumes you have already done that.
Then, when a disaster occurs, you will need to create the good place, by bringing up your workload in your recovery Region. You can do this automatically with tools such as AWS Elastic Disaster Recovery (DRS) which works for server-based workloads, or Arpio Disaster Recovery which works with multiple AWS resources including serverless and containerized workloads. You can also engineer your own automation per workload using tools like Amazon EventBridge and Amazon Lambda.
Figure 1. The good place and the bad place – When disaster strikes ensure your users go to the good place.
Once your recovery region is up and running, you’ll need a way to direct your users to it.
That is the focus here: how to make sure your customers reach the good place. In other words, how to implement effective failover routing.
Failover routing options
There are several technologies you can use for failover routing. Here I will focus on using DNS (Domain Name System), and specifically Amazon Route 53, as the technology of choice. A DNS record is a database entry that maps domain names to IP addresses or other resources. So given that your users or services access your workload through a domain name, this is a great way to re-map this domain name away from the bad place endpoint and to the good place one.
There are several failover routing strategies you can implement using Route 53. I will walk you through them using characters from The Good Place. For those unfamiliar with The Good Place, it’s a comedy about four recently deceased individuals humorously navigating the afterlife, trying to find their way between the “Good Place” (a version of heaven) and the “Bad Place” (a version of hell). Let us explore how each will try to get your users to the good place, during disaster recovery.
The “Jason” – Update your DNS records to route users
Jason is direct and without nuance. And a direct way for you to route users to your recovery region is to update your DNS records in Route 53.
Jason, however, is also a risk taker. His favorite way to solve most problems is to chuck a firebomb at it. And while this works a surprising number of times, sometimes (believe it or not) it backfires with disastrous results. Similarly, the “update your DNS records” strategy carries some risk. Updating DNS records is what AWS calls a control plane operation.
- Control plane operations are the CRUD type operations. These include updating a Route 53 DNS record, creating a new Amazon EC2 instance, or changing the throughput on an Amazon DynamoDB table.
- Data plane operations are what provide the primary function of the service, such as running EC2 instance itself, getting and putting objects in an S3 bucket, or resolving a DNS query.
[Read more about control planes and data planes here]
Control plane operations are by design less resilient than data plane operations. And for global services – which are services not associated with a specific AWS Region, such as Amazon Route 53 – their control plane is hosted in a single AWS Region. This means there is additional risk that if the region hosting the control plane is affected by the disaster, then you may not be able to issue control plane operations reliably. This is what happened December 7, 2021:
Several AWS services experienced impact to the control planes that are used for creating and managing AWS resources…. Route 53 APIs were impaired from 7:30 AM PST until 2:30 PM PST preventing customers from making changes to their DNS entries, but existing DNS entries and answers to DNS queries were not impacted during this event.
Existing DNS entries and answers to DNS queries were not impacted during this event because those are data plane operations.
But do not think that this “update your DNS records” strategy is necessarily a bad choice. Like Jason’s firebombs it will work most of the time. The December 2021 event was one of the very few times on record that AWS has experienced a complete outage of the Route 53 control plane. Just know if you adopt this strategy, you are assuming some extra risk. If you do go this route, then it is essential that you automate it using the AWS command line interface (AWS CLI) or the AWS SDK. You do not want to have a person mucking around with the AWS console, or even manually issuing CLI commands when you need to failover. Instead your operator should run the automation script.
One thing to consider is using this strategy as a stepping-stone. Start with it, but then evolve to one of the less risky ones.
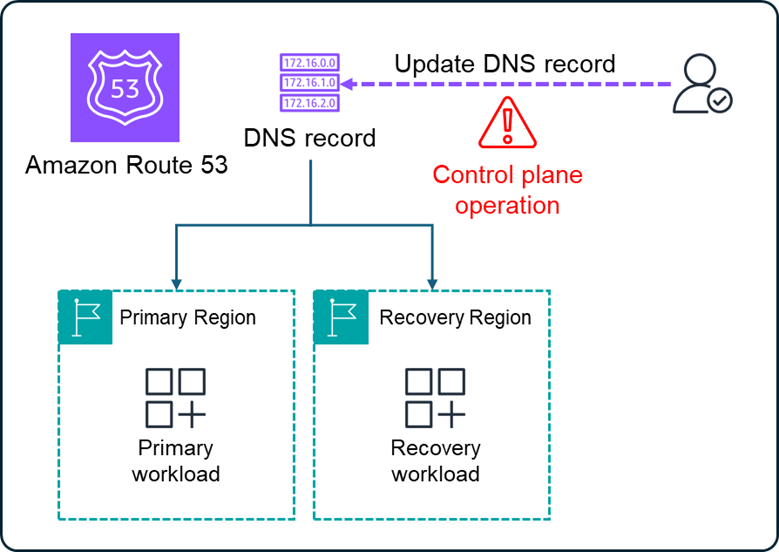
Figure 2. Updating Amazon Route 53 DNS record to change the Region users are routed to.
The “Chidi” – Automatic failover routing using health checks
Chidi is a well-studied professor always in search of knowledge. With this strategy your workload routing will automatically cut over based on knowledge from your metrics data. A Route 53 health check on your primary Region can be based on Amazon CloudWatch alarms, which indicate there is a problem. For example, when the 5XXError metric from an Application Load Balancer (ALB) exceeds a threshold it can change the Route 53 health check to unhealthy. Route 53 failover routing will then automatically stop sending traffic to the unhealthy primary Region and send the traffic to the good place instead. This action of changing the routing in response to a health check is a data plane operation, so there is no control plane risk here.
But Chidi also has a lot of trouble making decisions. In this strategy can you be sure that the alarm you configured truly means it is time to fail over? For many workloads, there is a real cost to failover in terms of lost data (recovery point) and downtime (recovery time), so you never want to fail over unnecessarily. Chidi is never sure if he has made the right decision – are you able to engineer health checks that are “sure” that it is time to fail over? This is a hard technical challenge, which is why in many cases it is recommended that failover be highly automated, but human-initiated. However, if you are sure of your rock-solid alarms, or alternatively there is little consequence to failover (this is possible with simple stateless workloads), then this may be the strategy for you.

Figure 3. Automatic failover with Amazon Route 53 failover routing using health checks with no human involvement.
Although we are focused here on Route 53 and DNS, there is also another AWS service that offers a form of failover routing based on health checks. Amazon CloudFront offers origin failover, where if a given request to the primary endpoint fails, CloudFront routes the request to the secondary endpoint. Unlike the failover operations described previously, all subsequent requests still go to the primary endpoint, and failover is done per each request.
The “Tahani” – Use Amazon Application Recovery Controller (ARC)
Tahani is the epitome of class and sophistication – she embraces only the finest that life offers. Similarly, Amazon Application Recovery Controller (ARC) is the gold standard solution for failover routing. It provides five highly available data plane APIs, each in a different AWS Region. Through this API you can initiate failover of traffic to a different AWS Region. The way it works is using the same Route 53 failover routing and health checks we already covered (The “Chidi”). But the Route 53 health checks in this case are not based on some metric, but are directly controlled by you, via the ARC API. ARC calls these “routing controls.” Using a script to call the APIs with the appropriate arguments is a highly automated but human-initiated process, and all done using data plane only.
Tahani’s sophisticated tastes however come at a cost. Using ARC, you can expect to pay about $1800 or more per month per cluster (using pricing in November 2024 when this post was published), and you may need several clusters. Although it looks like you can share a single cluster across AWS accounts, which should help to keep costs more reasonable for disaster recovery across multiple accounts.
And ARC provides more than just routing controls. With ARC you also get safety checks you can configure (for example, you might want to prevent inadvertently turning off all the routing controls for an application) and readiness checks (which check if your resources in your recovery Region are ready to take traffic).
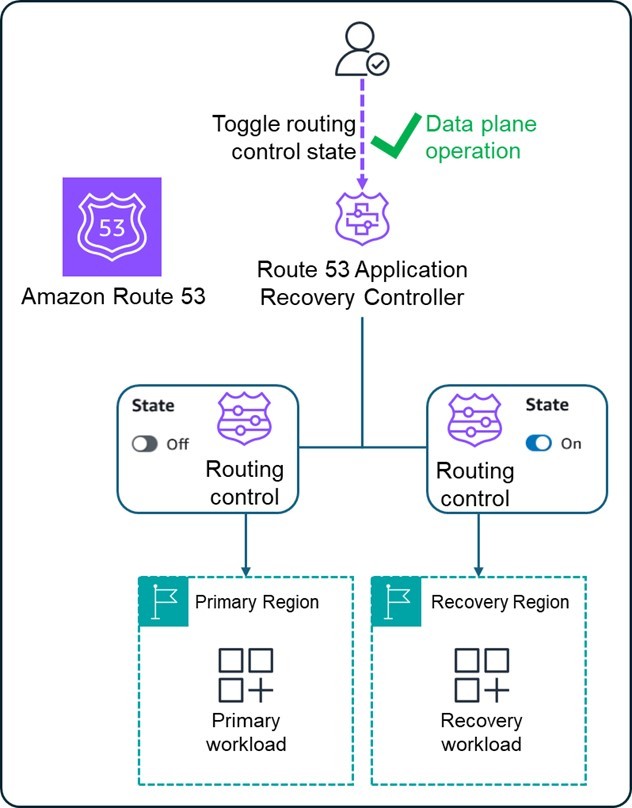
Figure 4. Route 53 Application Recovery Controller (ARC) enables you to set routing controls using a highly available data plane operation.
The “Eleanor” – Standby takes over primary (STOP)
Eleanor is pragmatic and crafty. She does not have Tahani’s budget, but she knows what she wants. Standby takes over primary (STOP) is a way to design a failover solution that uses Route 53 health checks and Route 53 failover routing but allows you to manually control the failover without needing to use Application Recovery Controller (ARC). Think of it as a “roll your own” version of ARC.
You can set up a Route 53 health check that monitors an HTTPS endpoint. Specifically, the health check looks for a file on a public S3 website in the recovery (aka standby) Region:
https://<FAILOVER-BUCKET>.s3.<STANDBY-REGION>.amazonaws.com/initiate-failover.html
Whether the file exists or not determines the state of the health check. Since deleting or putting a file on S3 is a data plane operation, this approach gives you control over the failover routing without the risks of using the control plane. For more details on Standby takes over primary, see this blog post.
STOP is a routing control mechanism. Remember that with ARC you get routing control, but you also get safety checks and readiness checks. So, take this into account when deciding whether to use ARC or STOP.

Figure 5. Standby Takes Over Primary (STOP) uses a data plane action in the standby Region, like adding or removing an object in Amazon S3, to control user routing between Regions
Layers of the stack
In this post, I’ve focused on a single endpoint. However, many workloads involve multiple endpoints: a user-facing website endpoint plus one or more backend API endpoints that the website calls to trigger specific functions. You need to implement failover routing for each of these endpoints to successfully fail over your workload and ensure users reach the good place for all layers of the stack.
Finding Your “Good Place” in Disaster Recovery: A Summary
Much like The Good Place, where every character embarks on a journey of growth, your disaster recovery strategy is about finding the best path to ensure your customers end up in their “Good Place”—your recovery region. In this article, we’ve mapped several failover strategies to the characters from the show, giving you a guide to navigating failover routing scenarios:
- The “Jason”: A direct approach — manually update Route 53 DNS records. It’s effective but carries risks due to reliance on AWS control plane operations.
- The “Chidi”: Automatic failover with Route 53 health checks — like Chidi, it’s thorough but potentially indecisive. It removes manual intervention but requires precise health checks to avoid unnecessary failovers.
- The “Tahani”: Use Amazon Application Recovery Controller (ARC) — a sophisticated and resilient solution with a cost. ARC offers high availability and direct control over failover via data plane operations.
- The “Eleanor”: Standby takes over primary (STOP) — pragmatic, cost-effective, and human-initiated without the risks of control plane reliance, making it a DIY version of ARC.
In the show, the characters learn that getting to “The Good Place” requires making choices, embracing flaws, and evolving strategies. Your disaster recovery journey is similar: understanding the risks, evaluating your budget, and deciding which approach best aligns with your needs. Whether it’s a Jason firebomb or Tahani-level sophistication, just remember that the ultimate goal is to ensure your customers end up in their “Good Place.”
How about the others?
There are many other unforgettable characters from the show that I did not mention. Michael is an architect, so surely there is a role for him here. And of course, we need to include Janet, Sean. and Mindy St. Claire. I have avoided any spoilers in this post.
Resources
AWS whitepaper on how to implement disaster recovery for workloads on AWS: Disaster Recovery of Workloads on AWS: Recovery in the Cloud
Blog series covering DR strategies: Disaster Recovery Series – AWS Architecture Blog
Essential concepts for building resilient applications in the cloud on AWS: Four Things Everyone Should Know About Resilience
Disaster recovery platforms to automatically stand up your recovery workload in the good place
by Seth Eliot, originally published on LinkedIn
